The manipulated variable in an experiment is the variable that is changed or “manipulated” in order to understand its effect on the dependent variable. The manipulated variable is also known as the independent or explanatory variable.
The manipulated variable is under the control of the researcher. The researcher changes the value of the manipulated variable to study the corresponding changes in the response/dependent variable.
We now give some examples of manipulated variables
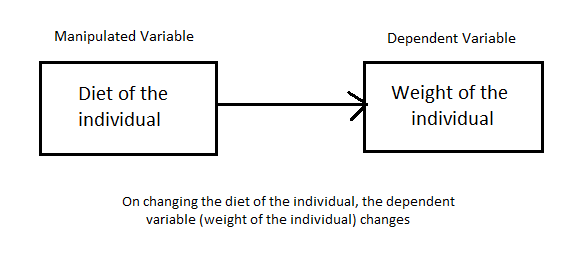
Example 1: Diet vs Weight Loss
Suppose we conduct an experiment to study the effect of diet on the weight of individuals. Here the diet is under the control of the researcher. The researcher can choose different diets and observe the effects due to them on the weight of the person. Since the diet is being controlled (“manipulated”) by the researcher, the diet is the manipulated variable.
Example 2: Rainfall vs Girth of Trees.
Suppo the effect of rainfall levels on the girth of trees. It is natural to expect that a higher amount of rainfall would lead to greater growth which should in turn cause the girth of trees to increase.
The researcher can choose to study two different areas where the amount of rainfall is low and high respectively and compare the girth of the trees in the two areas. Here the rainfall levels are the independent (manipulated) variable and the girth of trees is the dependent variable.
Example 3: Quality of Fuel and Mileage
Suppose that we conduct an experiment in order to understand the relationship between the quality of fuel and the mileage of a car. Here the researcher can choose different types of fuel and test which fuel offers the best mileage.
Hence the fuel quality is the manipulated variable and the resulting mileage of the car is the response variable.
Example 4: Exam Scores and Study Time
It is reasonable to expect that the more time an individual spends studying the better their performance in the exam.
When we are modeling the effect of hours spent studying by students on the marks obtained in a test, the number of hours spent can be varied, and hence it is the manipulated variable. The marks obtained in the test are the dependent/response variable.
Manipulated Variable vs Control Variable:
In a statistical model, there are generally 3 kinds of variables – manipulated variable, control variable, and response variable. The manipulated variable must not be confused with the control variable.
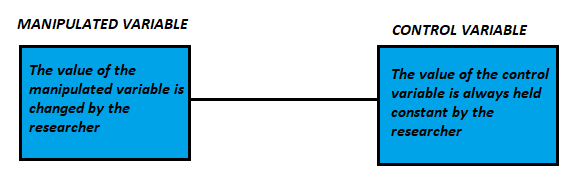
The main difference between a manipulated variable and a control variable is that the value of the manipulated variable is always changed by the researcher but the value of the control variable is always held constant by the researcher.
For example, if we are studying the effect of diet on weight loss we must make sure that all the individuals have the same exercise regimen to understand the true effect due to the diet.
In this case, the exercise regimen is the control variable. The diet followed by the individual is the manipulated variable and the weight is the response variable. Changing the diet leads to a change in the weight of the individual.
Manipulated Variables in Process Control:
Process control means controlling a process to make sure that it is cheap and as efficient as possible. In process control, we deal with two kinds of variables – manipulated variables and disturbance variables. The disturbance variables affect the output of our process.
For example, suppose that we have a factory that manufactures car parts. The process of manufacturing is affected by many different disturbance variables such as friction between the machine parts. The amount of electricity consumed by the factory is the manipulated variable and the car parts that are produced are the final output of the process.